Round 1 · 哪一张照片不是 AI 生成的?
Round 2 · 哪一张照片不是 AI 生成的?
近距离再看一遍
看看 AI 到底能做到多真
用肉眼区分 AI 图片和真实照片,
对正常人类来说已经基本不可能了。

01文生图的六个阶段之一
"能画了" 阶段
AI 第一次学会从零生成图片,但听不懂人话
约 2,555 天
2014.6 → 2021.1
2014 年一个叫 Goodfellow 的人发明了让 AI 互相对抗来学画画的方法。到 2018 年出现了一个网站——上面每一张人脸都是 AI 生成的,不存在的人。但这时候你没法告诉 AI 你想画什么。
本阶段主角
StyleGAN
NVIDIA · 2018.12
第一次让 AI 人脸逼近真实——"这个人不存在" 网站引爆公众对 AI 造假的认知
关键事件 · 5 个
2014.6
AI 第一次学会凭空造一张不存在的图
Ian Goodfellow 等人在 NeurIPS 发表 GAN(对抗生成网络)论文。核心思想:让两个神经网络互相对抗——一个"造假者"不断生成图像、一个"鉴别者"不断识别真伪,直到造假的以假乱真。这是第一种能"无中生有"的图像生成方法。
2017.10
AI 人脸第一次逼近真实
NVIDIA 的 Tero Karras 等人发表 Progressive GAN(后改进为 StyleGAN)。训练出来的人脸质量首次到达"肉眼难辨"水平。
2018.2
"这个人不存在"网站上线,公众第一次大规模感受 AI 造假
thispersondoesnotexist.com 每次刷新随机出现一张由 StyleGAN 生成、从未存在的人脸。几天内在社交网络疯传。
2018.10
AI 画作第一次进入艺术拍卖市场
佳士得(Christie's)拍出法国艺术团队 Obvious 用 GAN 生成的《Edmond de Belamy》,成交价 $432,500。AI 作品被作为"艺术品"在主流艺术市场定价。
2021.1
第一次用一句话就能让 AI 画图 · DALL·E 1
OpenAI 发布 DALL·E(第一代)。把文字和图像放进同一个编码空间。用户输入"牛油果形状的沙发"(an armchair in the shape of an avocado),AI 第一次能画出来。质量粗糙,但"文字→图像"的桥梁正式搭好。
02文生图的六个阶段之二
"换画法了" 阶段
扩散模型诞生,画质飞跃,后来还变得快了几十倍、便宜了几十倍
约 670 天
2020.6 → 2022.4
Rombach(德国)发明了一种方法,不再用生成器和判别器互相博弈,而是先铺满噪点,再一轮一轮按要求把画面"显影"出来。
本阶段主角
DALL·E 2
OpenAI · 2022.4
扩散模型第一次做出让大众疯狂的产品——发布当天 100 万人排队申请内测,"AI 绘画"第一次成为大众话题
关键事件 · 3 个
2020.6
有人发明了一种更好的画图方法——从噪点里慢慢还原出图像
UC Berkeley 的 Jonathan Ho 等人发表 DDPM(Denoising Diffusion Probabilistic Models)论文。不再是 GAN 的"一次生成",而是从一张纯噪点开始,让 AI 逐步去除噪点、直到还原出一张图像。结果比 GAN 更稳定、更清晰。
2021.12
新画法被改造得又快又便宜——让"家用显卡能跑"成为可能
Robin Rombach(慕尼黑大学)等人发表 Latent Diffusion Models 论文。关键改进:不在原始图像像素上去噪,而是在"压缩版的图像空间"里去噪,算力需求降低几十倍。这是后来 Stable Diffusion 能跑在家用显卡上的核心技术。
2022.4
DALL·E 2 让全世界第一次为 AI 绘画排队
OpenAI 发布 DALL·E 2。用 Diffusion + CLIP 的组合,画质相比一代是质变。发布当天就有 100 万人排队申请内测。从这里开始,"AI 绘画"第一次成为大众话题。
03文生图的六个阶段之三
"普通人能用上" 阶段
三个爆款产品同时出现,普通人第一次能用上
约 120 天
2022.4 → 2022.8
120 天内三个产品同时引爆——DALL·E 2 走封闭精品路线,Midjourney 走社区美学路线,Stable Diffusion 走开源免费路线。这三条路线的分歧一直延续到今天。
本阶段主角 · 三路并起
DALL·E 2
OpenAI · 2022.4
封闭精品路线——邀请制、严格审核
Midjourney
Midjourney · 2022.7
社区美学路线——Discord 上起家
Stable Diffusion
Stability AI · 2022.8
开源普惠路线——家用显卡免费跑
关键事件 · 3 个
2022.4
DALL·E 2 打响第一枪——封闭精品路线
OpenAI 的策略:邀请制、严格审核、商业化谨慎,由官方控制质量和品牌形象。
2022.7
Midjourney 开放 Beta——社区美学路线
David Holz(前 Leap Motion 创始人)的小团队做的产品,核心哲学是"美学感"。不用自己训练、不用 API——在 Discord 上输入一条命令,几秒钟出图。这种体验和社区氛围,让 Midjourney 快速聚集第一批 AI 艺术家。
2022.8
Stable Diffusion 开源——AI 绘画的"安卓时刻"
Stability AI 把 LDM 论文的代码和模型权重全部开源。任何人可以下载到自己的电脑上免费跑。接下来 3 个月里,民间涌现出 LoRA、ControlNet、WebUI 等工具,整个生态被彻底点燃。
04文生图的六个阶段之四
"好看但是瞎画" 阶段
画质以假乱真,但 AI 不理解自己在画什么
约 940 天
2022.8 → 2025.3
画面精致到让人分不清是不是摄影。但你让它在蛋糕上写 Happy Birthday,它写出来的是 Hapy Brithday。好看,但它不懂自己在画什么。
本阶段主角
Midjourney v5
Midjourney · 2023.3
"AI 画的图第一次让人觉得不像 AI 画的"——画质巅峰的代表,此后两年的自媒体默认工具
关键事件 · 6 个
2022.10
开源社区三个月造出几百个专用模型
LoRA 让普通人用几百张图就能训练专属风格;ControlNet 让 AI 遵守人体姿态、深度图等精确控制;WebUI(Automatic1111)把这些工具整合成浏览器界面。这个生态的爆发速度超过闭源产品。
2023.3
Midjourney v5 第一次让 AI 画的图不像 AI 画的
v5 的画质在"摄影感"上出现质变——光线、纹理、皮肤都足够真实,几乎成为自媒体内容的默认选择。
2023.9
DALL·E 3 第一次让 AI 懂"对话式"改图
OpenAI 把 DALL·E 3 绑进 ChatGPT。用户可以说"把帽子改成红色"、"把人的表情变严肃"。但仍是"ChatGPT 改 prompt 再喂给 DALL·E 3"的两段式,不是一个模型真的理解画面。
2024.7
开源派反攻——FLUX.1 把开源画质拉到商业第一梯队
Robin Rombach(原 SD 架构师)离开 Stability AI 后创立的公司 Black Forest Labs 发布 FLUX.1。画质、语义遵从度都达到当时 SOTA 水平。
2024.8
学术界为下一代范式铺路
Meta AI 发表 Transfusion 论文,提出 AR + Diffusion 混合架构——语言用自回归生成、图像用扩散生成,共享一套 transformer 主干。为后来的 GPT-4o 原生图像生成做理论铺垫。
2025.3
Midjourney v7 文字渲染提升——但在同期已不是最强
文字准确率提升约 65%,但在同月的 Arena 评测中已明显落后 GPT-4o。"文字渲染"这块山头易主。
05文生图的六个阶段之五
"听懂了要画什么" 阶段
AI 终于理解了你在说什么
约 390 天
2025.3 → 2026.4
画图的'大脑'和理解语言的'大脑'是同一个。吉卜力风格头像一夜之间刷屏全网,首周 1.3 亿用户生成了 7 亿张图。
本阶段主角
GPT-4o 原生图像
OpenAI · 2025.3
从扩散 → 自回归的范式转变,图像生成第一次和语言理解共享一个模型;吉卜力风格全网刷屏,首周 1.3 亿用户生成 7 亿张图
关键事件 · 7 个
2025.3
GPT-4o 原生图像生成——吉卜力风格全网刷屏
第一个用自回归方式(像写作一样一个 token 一个 token)生成图像的大规模商用模型。关键改变:图像生成和语言理解共享同一个模型,而不是两个。用户发现它能正确画字、数对物体数、懂复杂指令。首周有 1.3 亿用户生成 7 亿张图。
2025.4
API 开放——开发者可以把这个能力接进任何产品
gpt-image-1 API 正式开放,单张图成本约 $0.02-0.08。
2025.8
Google 偷偷参加匿名考试拿了第一
用代号 Nano Banana 匿名参加 Arena 榜单,数周内拿到第一。揭晓身份后产品爆火,迅速追到 OpenAI 脚边。
2025.10
便宜版来了——成本降 80%
OpenAI 发布 gpt-image-1-mini,单张图成本降到 $0.006,适合大规模低成本场景。
2025.11
OpenAI 宣布 DALL·E 将于 2026.5 退役
独立图像模型的讣告——连 DALL·E 3 的母公司自己都选择放弃"独立图像模型"这条路,全面转向"通用模型做图"。
2025.12
OpenAI 反攻——gpt-image-1.5 重回 Arena 第一
Elo 1,271 分,Nano Banana 暂时被拉开差距。
2026.2
Google 再次逼近——差距缩到 7 分
Nano Banana 2 发布,Arena Elo 1,264 — GPT Image 1.5 的 1,271 仅领先 7 分。此时所有人都在等 OpenAI 拿出下一招。
06文生图的六个阶段之六 · 当下
"会想了" 阶段
AI 第一次"想一想"再下笔,复杂任务一次完成
3 天
2026.4.21 → 至今
本阶段主角
GPT Image 2.0
OpenAI · 2026.4.21
首个具有原生推理能力的图像模型——生成前先"思考规划",然后分步生成、自我验证;Arena 榜单 +241 分 历史最大领先
关键事件 · 4 个
2026.4.4
三个神秘模型短暂出现在 Arena 榜首——几小时后消失
代号 packingtape / maskingtape / gaffertape 三个模型匿名出现,被社区识别为 OpenAI 在 Arena 上的"秘密考试"。
2026.4.21
GPT Image 2.0 正式发布——首个带"推理"的文生图模型
关键特性 · Thinking Mode:生成前先用语言"思考规划"(例如"这张图有 5 个对象,布局应该是……"),然后分步生成,并自我验证。复杂指令第一次能一次性到位。
2026.4.22
Arena 榜单公布——1,512 分,+241 领先第二名
Arena.ai 历史上最大的领先差距。横扫全部 7 个子类别,文字渲染子类别 +316 分。
2026.5.12
DALL·E 2/3 API 正式退役(预定)
独立图像模型时代正式落幕。
把六个阶段放在一条时间轴上
从 GAN 论文到此刻,12 年。而你看到的所有"AI 绘画爆发",都是最近这 3 年里的事。
六大产品 · 八个维度
客观 benchmark + 厂商声明 + 媒体估算——每个数据的来源类型都明确标注。


把所有模型放回理解力阶梯
画质的差距在缩小——理解力的差距才是真正的代际鸿沟。
独立图像模型 vs 能做图的通用模型
2026 年,这个行业正在发生一次结构性迁移。
左侧
独立图像模型
▼ 在减少
右侧
能做图的通用大模型
▲ 在增加
DALL·E 2/3 将于 2026.5.12 退役——连发明独立图像模型的公司,都亲手关掉了它。
当独立模型的厂商都选择并入通用模型,这不是产品迭代,是赛道切换。
Chapter 1 · 文生图 · 完
文生图
已经毕业了。
+241
Arena 榜单差距 · 历史最大领先幅度
99%+
文字渲染准确率
L4
刚进入"推理驱动"层级——新阶段的第 3 天
那文生视频呢?
是同一件事、同一条路径吗?
还是完全不同的故事?
还是完全不同的故事?
Chapter 2 · 接下来
文生视频 — 收敛陷阱 与 品味红利
Chapter 2
文生视频
从"能动了"到"对得上了"
文生图和文生视频共享同样的理解力基础。
但文生视频还有一个文生图没有的难题——一致性。
一张图只需要好看一次,一段 15 秒的视频需要好看 450 次,而且 450 次之间要完美对齐。
但文生视频还有一个文生图没有的难题——一致性。
一张图只需要好看一次,一段 15 秒的视频需要好看 450 次,而且 450 次之间要完美对齐。
文生视频的专属难题 · 一致性阶梯
以前"不能用"不是画质差——单帧截图往往还不错。连起来播放时,人脸变形、物体闪烁、画面抖动。
文生图 vs 文生视频 · 同一把尺
文生视频晚起步 8 年,但从"能用"到"跨过门槛"只用了不到 2 年。
01文生视频的四个阶段之一
"能动了" 阶段
AI 让图片动起来了,但连"不变形"都做不到
约 730 天
2022 → 2024.2
2023 年之前,AI 视频就是模糊的几秒钟。Runway 是第一个吃螃蟹的人——它证明了"花钱用 AI 做视频"这件事是可能的,虽然效果还很粗糙。
本阶段主角
Runway Gen-1 / Gen-2
Runway · 2023.2-3
第一个普通人花钱就能用的文生视频产品——证明"AI 做视频"这件事是可能的
关键事件 · 3 个
2022
CogVideo(清华 / 智谱)
最早的大规模文生视频模型,仍然是学术实验,没有面向公众的产品。
2023.2-3
Runway Gen-1 / Gen-2 发布
第一个花钱就能用的文生视频产品。Gen-1 做视频转视频(风格迁移),Gen-2 做文字到视频。效果粗糙但证明了商业化方向。
2023.11
Stable Video Diffusion 开源
Stability AI 把视频生成模型也开源了,开源社区正式进入视频领域。
02文生视频的四个阶段之二
"像真的了" 阶段
Sora 的一段演示视频改变了所有人的预期——但只能看不能用
约 298 天
2024.2 → 2024.12
Sora 在 2024 年 2 月展示了"AI 视频可以这么真实"。OpenAI 自己把它叫做视频领域的"GPT-1 时刻"。但从演示到公开可用,中间隔了 10 个月——这段时间里 Runway、Kling、Luma 拼命追赶。
本阶段主角
Sora 预览
OpenAI · 2024.2.15
文生视频的"ChatGPT 时刻"——1 分钟高清视频 + 物理模拟震惊全场;但只能看不能用
关键事件 · 3 个
2024.2.15
Sora 预览发布
OpenAI 公布 1 分钟高清视频 demo,物理模拟(液体、光影、物体互动)震惊全场。官方称之为视频领域的"GPT-1 时刻"。
2024.6
Gen-3 / Kling 国际版 / Luma 同月发布
Sora 打开想象力后,能用的产品开始集中涌现——Runway Gen-3(高清)、Kling 国际版、Luma Dream Machine 同一个月登场。
2024.12.9
Sora Turbo 公开
从演示到公开可用隔了 10 个月。质量仍然不稳定,首次命中率低。
03文生视频的四个阶段之三
"能用了但像抽卡" 阶段
画质能骗过人眼了——但 10 次生成只有 2 次能用
约 540 天
2024.6 → 2025.12
这个阶段画质已经能骗过人眼了——Runway 找了 1043 个人做测试,90% 的人分不出 AI 视频和真实视频。但核心问题是首次命中率只有 ~20%——用 10 次大概 2 次能用。用起来像抽卡,所以只有早期玩家在用,公司还不敢拿来赚钱。
本阶段主角 · 两路并起
Runway Gen-4.5
Runway · 2025.12
图灵测试 1043 人中 90%+ 无法区分 AI 视频和真实视频(5 秒精选片段)
Kling O1
Kuaishou · 2025.12.1
生成+编辑+参考+转场整合到一个模型,工作流统一化
关键事件 · 3 个
2025.5.20
Google Veo 3
首个原生音视频同步的主流模型——在生成画面的同时生成环境音和对话。
2025.12.1
Kling O1
生成、编辑、参考、转场整合到一个模型里,工作流第一次统一化。
2025.12
Runway Gen-4.5 · 图灵测试 90% 无法区分
Runway 找了 1043 个人做测试,90% 分不出 AI 视频和真实视频(5 秒精选片段)。画质上限证明够用,但抽卡式命中率还是卡住了商业化。
04文生视频的四个阶段之四 · 当下
"对得上了" 阶段
声画同步、命中率 90%——从"抽卡"变成了"工具"
约 77 天
2026.2 → 至今
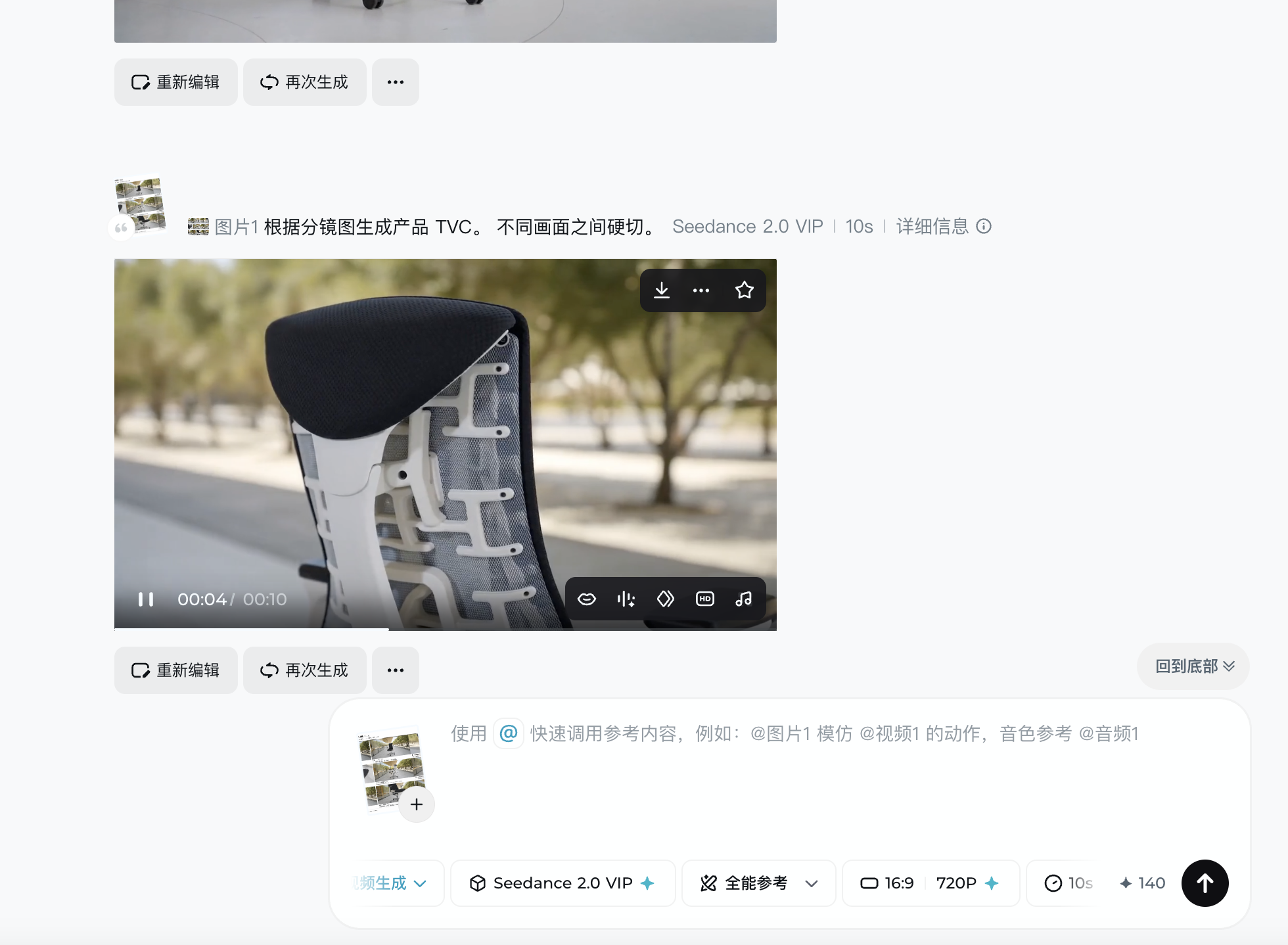
Seedance 2.0 把声音、画面、动作对齐到同一个模型里。首次命中率从 20% 跳到 90%——短剧公司涌进来了,央视春晚的"十二花神"也是它做的。
本阶段主角
Seedance 2.0
ByteDance · 2026.2.12
音视频联合生成 + 首次命中率 ~90% + 央视春晚"十二花神"
Seedance 2.0 做对了三件事
01
统一模型
以前是"画面 + 音频 + 唇形同步"三个模型拼接,每一步都引入误差。Seedance 2.0 一个模型一次性输出——跟 GPT Image 2.0 的 Thinking Mode 同一方向。
02
字节的数据优势
抖音和 TikTok 是全世界最大的短视频数据库。模型见过几十亿条"人说话时嘴型""跑步时脚步频率"的真实样本。
03
首次命中率跃迁
行业平均 ~20% → Seedance ~90%。短剧公司涌进来的真正原因不是"画质好了",而是"效率够了"。
关键事件 · 5 个
2026.2.5
Kling 3.0 · AI 导演
4K / 60fps,6 镜头叙事。6000 万用户,$2.4 亿年化收入。
2026.2.12
Seedance 2.0
音视频联合生成,命中率 ~90%。央视春晚"十二花神"。冯骥:"AIGC 的童年时代结束了。"
2026.3.24
Sora 关停
终身收入 210 万美元,每天烧 1500 万。一家的退出 ≠ 行业失败——正是行业进入商业化的副产物。
2026.4.7
HappyHorse 登顶 Arena
Kling 前架构师张迪跳槽阿里做出的新模型,登顶 Arena Video 榜首。
2026.4
Veo 3.1 免费开放
任何 Gmail 账号每月 10 次免费——Google 把视频生成能力下放给所有人。
心智模型
首次命中率
≥ 50% 才有机会进入日常工作流("工具")
< 30% 只适合平时玩玩("抽卡")
心智模型 · 4
首次命中率 · 抽卡 vs 工具的分水岭
≥ 50% 可以进入日常工作流("工具")· < 30% 只适合碰运气("抽卡")
心智模型
品味门槛
当大多数观众已经分不出 AI 作品和人类作品的区别时,
拼的就是品味和意图。
参考例子
手机摄影 · 一个已经跨完门槛的品类
看看当"人人都能拍出好照片"之后,真正的护城河变成了什么
2007 年 iPhone 让人人都有了相机。但接下来十几年,专业摄影师的地位没变——因为手机画质还是比不过单反。
直到 2024 年前后的一代旗舰(vivo X200 Pro / iPhone 16 Pro Max),计算摄影让手机拍出的画面,普通观众已经分不出是单反还是手机。
这一刻,摄影师的护城河变了——从"有器材 + 会用设备",变成了"构图、审美、时机"。
直到 2024 年前后的一代旗舰(vivo X200 Pro / iPhone 16 Pro Max),计算摄影让手机拍出的画面,普通观众已经分不出是单反还是手机。
这一刻,摄影师的护城河变了——从"有器材 + 会用设备",变成了"构图、审美、时机"。
跨门槛的时间线
2007
iPhone 1 代
相机普及的起点
~2012
计算摄影雏形
HDR 开始走向主流
~2018
夜景模式
画质接近中端单反
~2024
旗舰机世代
画面已经分不出来源 ★
摄影师的护城河变了
跨过之前
- 有好设备
- 会用器材
- 暗房 / Photoshop 技巧
工具 / 技术能力
→
跨过之后
- 构图决策
- 审美判断
- 时机把握
- 对观众的理解
品味 / 判断力
展望 · 4 个前沿方向
视频生成的下一步
01
推理型视频模型
生成前先"想",分镜规划再出片——跟 GPT Image 2.0 同思路
代表 Luma Ray3 · 即梦 Agent 模式
02
时长突破
从 15 秒走向 3 分钟——长片连贯性的第一个拐点
代表 Kling 3.0 延长至 3 分钟
03
统一工作流
生成 + 编辑 + 参考 + 转场在一个模型里——不再拼接多个产品
代表 Kling O1 · 剧火平台
04
世界模型(完全不同的赛道)
视频生成的"终点"不是"更好的视频"——而是让世界在镜头里运行,不是在 prompt 里生成。被认为是"大语言模型之后最重要的赛道"。
代表 Odyssey-2 Max(4.22 发布) · Yann LeCun AMI Labs(融 5 亿欧元)
但也别神话 · 4 个当前瓶颈
这些地方还做不到
01
长片连贯性
15 秒内超过中位导演,但 3 分钟以上的叙事连贯性还不稳定
对我们的影响
评测完整片段仍需实拍
02
真人面部精度
微表情、牙齿、头发边缘——这些细节还会被观众一眼识破
对我们的影响
出镜类内容仍需真人
03
版权法律灰色
Seedance 因好莱坞争议暂停全球推广;训练数据版权仍未解决
对我们的影响
商用时注意法律风险
04
同质化
所有人用同样工具,输出趋向同一种"AI 视频质感"
对我们的影响
需要有意识建立品牌视觉风格
Chapter 3
AI 对话
为什么 AI 越聊越笨?
前两章讲了"能力"——文生图学会思考,文生视频学会对齐。
这一章讲"记忆"——为什么 AI 有时像天才、有时像傻子。
关键在一个你每天都在经历、但可能从没想过为什么的概念:Context。
这一章讲"记忆"——为什么 AI 有时像天才、有时像傻子。
关键在一个你每天都在经历、但可能从没想过为什么的概念:Context。
AI 对话的六个阶段 · 快速过一下
这些你们都很熟了,不展开讲
2018
能说了
GPT-2
第一次生成像人写的文字,但经常胡说
2020
说得像了
GPT-3
写得像真人,但不能对话,普通人用不上
2022.11
能聊了
ChatGPT
两个月 1 亿用户 · AI 的 iPhone 时刻
2023.3
变聪明了
GPT-4
能看图、通过律师资格考试、真能干活了
2024.9
会推理了
o1 / DeepSeek-R1
数学准确率 13%→83%,先想步骤再说答案
2025.12
会干活了
Claude Code · Hermes
不只回答问题,自己动手做事
实例 · 1
实例 · 2
实例 · 3
实例 · 4
先问一个问题
不管是写稿、做方案,还是生活里遇到问题,
你去问 AI 的时候——你最佳的用法是什么?
你现在的痛点大概是这样的:
01
每个问题都要开一个新窗口
02
遇到同类型话题,每次都得重新交代背景
03
聊到后面,AI 开始"忘事"——你明明说过的要求它不执行了
04
让它改第三段,它改了第五段
理想的用法
应该是这样的
你跟 AI 之间只有一个窗口。
你所有的背景信息只输入一次——你的工作内容、你的偏好、你的项目进展。
当你说"这次是工作上的事",它就调用你所有工作相关的背景;
当你说"生活问题",它就切换到你的生活信息。
聊一个星期,它比新同事更懂你。
聊一个月,它是全世界最了解你的助手。
你所有的背景信息只输入一次——你的工作内容、你的偏好、你的项目进展。
当你说"这次是工作上的事",它就调用你所有工作相关的背景;
当你说"生活问题",它就切换到你的生活信息。
聊一个星期,它比新同事更懂你。
聊一个月,它是全世界最了解你的助手。
你可能会问:ChatGPT 不是有记忆了吗?Claude 不是也能记住我吗?
确实有。但你有没有发现——即使开了记忆,聊到后面 AI 还是会忘事?你给了一大段资料它只用了开头和结尾?要求越复杂它漏掉越多?
概念定义
Context · 上下文
AI 在回答你这一次提问时,能"看到"的全部信息
它包括
- 你写的系统提示词
- 你们之前的对话历史
- 你上传的文档
- AI 自己生成的回答
所有这些必须全部塞进
一个固定大小的"窗口"里
一个固定大小的"窗口"里
把它想象成一块白板
系统提示词...
你说:帮我写一份方案
AI:好的,需要哪些维度?
你说:预算、时间、资源
AI:让我整理一下...
...
(早期对话被擦掉)
白板写满了,最早的内容就被擦掉 · 白板之外的信息对 AI 来说不存在
Memory 的真相
Memory 本质是有损压缩
把过去几十轮对话"压缩"成几句话摘要,塞进下次对话的 Context 里
老同事手里的
📋 完整项目文档
📋 会议记录 · 百轮对话
📋 决策背景 · 踩过的坑
📋 细节与例外情况
📋 未成文的判断逻辑
压缩
→
新同事收到的
📄 200 字交接备忘
大概知道项目做什么
大量细节、决策背景、踩过的坑——全丢了
大量细节、决策背景、踩过的坑——全丢了
案例一
OpenClaw(小龙虾)
很强——但不会成长
现象
能连微信、飞书、终端,帮你发邮件、管日程
昨天教它怎么格式化日报,今天又忘了
纠正过它一个错误,下次还犯
每次会话结束,学到的东西清零
Context 视角
OpenClaw 的记忆是静态的
你手动写配置文件 → 它读取执行 → 会话结束什么都不留下
案例二
Hermes Agent
两个月 GitHub 8.8 万星 · "the agent that grows with you"
做了什么
每次任务完成后自检:值不值得记下来?
工具调用 > 5 次?中途出错自己修好?你纠正过?走过不明显但有效的路径?
如果有 → 自动生成 Skill 文件(一份 SOP)
下次遇到类似任务 直接复用——发现更好做法再打补丁,不重写
Context 视角
Hermes 让 Context 持久化
任务 → 沉淀 Skill → 下次继承 → 迭代修正 → 跨会话积累
上帝视角
问一个问题就能看穿本质
它怎么处理 Context?
新的 Agent 框架火了
→
它比前一个在 Context 管理上好在哪?
某个模型号称"1000 万 token 上下文"
→
有效上下文是多少?给它 100 万 token 它还能用好吗?
某个产品出了"记忆功能"
→
是有损压缩还是完整持久化?丢掉了什么?
某个 AI 工具"越用越好用"
→
它的 Context 是跨会话积累的吗?怎么积累的?
你自己用 AI 发现它变笨了
→
Context 可能已经"腐烂"——开个新窗口带着关键结论重新开始
AI 不笨。它只是"记不住"。
理解了 Context,你就理解了——
不是它的能力在波动,是它能"看到"的信息在变化。
AI 分享会 0423